
When cookies crumble and consent becomes the new currency, analytics doesn’t stop—it evolves. Artificial intelligence (AI) and machine learning (ML) are now the force multipliers that let teams extract business insight while honoring user rights. This isn’t about “doing the same, with less data.” It’s about asking better questions, at the right grain, with rigorous safeguards.
Below is a practical, business-focused overview of how AI fits into a privacy-first stack—what it’s good at, where it can mislead, and how to govern it responsibly. No how-to setup steps, just strategy you can act on.
What “privacy-first” means in practice
A privacy-first approach shifts analytics from user-level surveillance to purpose-bound, aggregate intelligence. Data collection is minimized, consent is respected, and algorithms operate with guardrails that prevent re-identification. In this model, AI’s job is to generalize—to learn patterns that inform decisions—without needing to profile individuals.
Key pillars:
- Data minimization: Capture only what answers a business question.
- Aggregation by default: Page, product, and cohort-level views over user trails.
- Explainability & transparency: Stakeholders understand what is modeled vs. observed.
- Accountability: Clear ownership, policies, and review cycles for models and metrics.
Where AI adds real value—without personal IDs
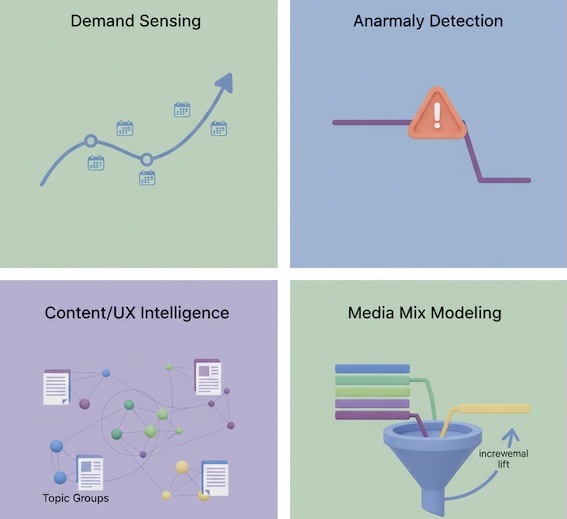
1) Demand sensing and forecasting
Even with consent gaps, ML can forecast traffic, signups, and revenue using aggregated time series (by channel, region, product). Models learn seasonality, promotions, and macro shifts to inform inventory, staffing, and campaign pacing—no identity required.
Business win: Stable plans, smarter capacity allocation, fewer “stock-outs” or wasted media.
2) Anomaly detection that respects privacy
Modern anomaly detection flags unexpected spikes/drops in aggregate metrics (visits, conversions, page groups). It can separate true issues (tracking breaks, outages, bot floods) from normal variance.
Business win: Faster incident response; fewer “false alarms” to executives.
3) Content and UX intelligence at page/cluster level
Clustering models group content by topic and intent, surfacing which themes attract qualified attention and which layouts under-perform. Because the unit of analysis is page or cohort, you gain insight without user stitching.
Business win: Invest in topics and templates that lift engagement and conversion.
4) Media effectiveness with privacy-safe modeling
With fewer user-level touchpoints, multi-touch attribution gets brittle. ML-based media mix modeling (MMM) and geo/temporal experiments estimate incremental lift from channels using aggregated data—robust against cookie loss.
Business win: Budget decisions grounded in incrementality, not click myths.
5) Quality and safety filters
AI helps filter bot traffic, detect scrapers, and identify data drift (e.g., events firing twice). These checks run on telemetry and server logs—not identity graphs.
Business win: Cleaner baselines; leadership trusts the numbers.
Techniques that balance insight and privacy
You don’t need the math under the hood, but you should know the guardrails that make AI privacy-fit:
- Differential privacy (DP): Adds calibrated noise so no single person’s data can be inferred from outputs. Think of it as “crowd blur” with provable guarantees.
- Federated learning: Models train where the data lives (device, region, or silo) and share only model updates, not raw records.
- On-device inference: Some predictions (like content recommendations) can run locally, using only the session’s context, then discard immediately.
- Secure aggregation: Encrypted contributions are combined into totals; no single record is visible to the coordinator.
- Synthetic data (with caution): ML generates statistically similar datasets for testing and exploration—useful, but validate to avoid leaking rare patterns.
These approaches protect individuals while preserving the signal that matters for decisions.
Metrics to monitor (and how AI reframes them)

- Observed vs. Modeled conversions: Report both. Observed = consented, directly measured. Modeled = statistically inferred to cover blind spots. This transparency prevents “mystery numbers.”
- Incrementality, not attribution chains: Use MMM or structured lift tests to answer, “What moved the needle?” rather than “Which click gets credit?”
- Engagement quality at the cohort level: Track engaged sessions per page cluster, scroll depth, and task completion—AI can benchmark cohorts without identity graphs.
- Forecast accuracy and stability: Hold models to business KPIs—MAE/MAPE for forecasts, precision/recall for anomaly alerts—so leaders trust automation.
Responsible use: questions leaders should ask
- Purpose: What decision will this model change? If we wouldn’t act differently, don’t collect or compute.
- Inputs: Are we using only necessary, low-risk signals (content, channel, device, time)?
- Privacy guardrails: Which protections are applied (DP, aggregation, on-device, regional boundaries)?
- Bias & fairness: Could the model disadvantage a segment (e.g., under-representing certain geos or devices)? What audits are in place?
- Explainability: Can we summarize why a prediction changed week-over-week—in plain language?
- Governance: Who owns the model, review cadence, and rollback criteria?
This governance checklist is as important as the model itself.
Common pitfalls—and better options
- Pitfall: Rebuilding user-level tracking via fingerprinting.
Better: Accept aggregate grains; invest in robust cohort analytics and lift tests. - Pitfall: Treating modeled numbers as facts.
Better: Label modeled metrics clearly; track uncertainty; show confidence ranges. - Pitfall: Chasing micro-optimizations with noisy signals.
Better: Focus on durable questions—topic demand, channel incrementality, UX friction by template. - Pitfall: Black-box vendor promises.
Better: Demand documentation on data flows, privacy techniques, and validation studies. No details, no deal.
Executive-level use cases to socialize
- Quarterly planning: AI-assisted forecasts per channel and product inform spend, hiring, and inventory.
- Content portfolio review: Topic clusters ranked by impressions → engagement → business outcomes, with model-adjusted coverage for consent gaps.
- Risk dashboard: Automated alerts for tracking breaks, Core Web Vitals regressions, and suspicious traffic patterns.
- Channel investment memo: MMM-based budget shifts with confidence intervals and scenario analysis (e.g., “+10% search vs. +10% video”).
Each use case is aggregate-first and privacy-respecting, yet concrete enough to steer budgets.
Continue Learning
Explore more privacy-first analytics strategies:
- First-Party Data Strategy — build analytics without third-party cookies
- CCPA, GDPR, and Beyond — navigate global privacy regulations
- Server-Side Tracking for Small Businesses — privacy-respecting data collection
The bottom line
AI is not a workaround for lost identifiers; it’s an upgrade in how we reason with data. In a privacy-first world, the winners will be teams that:
- Ask sharper business questions,
- Operate at the right level of aggregation,
- Use protective techniques by default,
- And hold models accountable to transparent, decision-grade metrics.
Do that, and you’ll deliver insights leadership trusts—without asking customers to trade away their privacy.
